Sentiment analysis
for tweets #spotify
This project was created to analyze the sentiment of people on
twitter regarding spotify.
I wanted to explore what kind of insights could be made using
pythons NLTK library
and word clouds.
Here is my sentiment analysis project of Tweets that include the
keyword spotify.
*All Tweets were fetced on 17.09.2022, between 22:00-24:00 EEST.
Positive sentiment

The final version of the Tweets that have a positive sentiment
negative sentiment

The final version of the Tweets with a negative sentiment
How we got there
First a collection of 2000 Tweets per word cloud were fetched using the Twitter API and the Tweepy library. Then the Tweets were given a sentiment score using NLTK and TextBlob libraries. This is the result of forming a word cloud of Tweets with negative sentiment before proper data cleaning and word processing, which will be done in the later stages.
Word cloud of Tweets with a negative sentiment, prior to data cleaning or word processing.
As we can see the word cloud includes items such as single letters and results from all languages, this will be taken care of in later stages. "spotify" is the top word for many searches because it's the keyword, it adds no value so this will be removed from the word cloud aswell.
Walkthough of the steps
Remove punctuation -> list comprehension & Regex
Tokenization -> Regex
Remove stopwords -> library nltk(stopwords)
Stemming the words -> library PorterStemmer
Applying final cleaning steps to tidy the text data.
Regex and list comprehension were extensively used in the transformation of data.
Final results
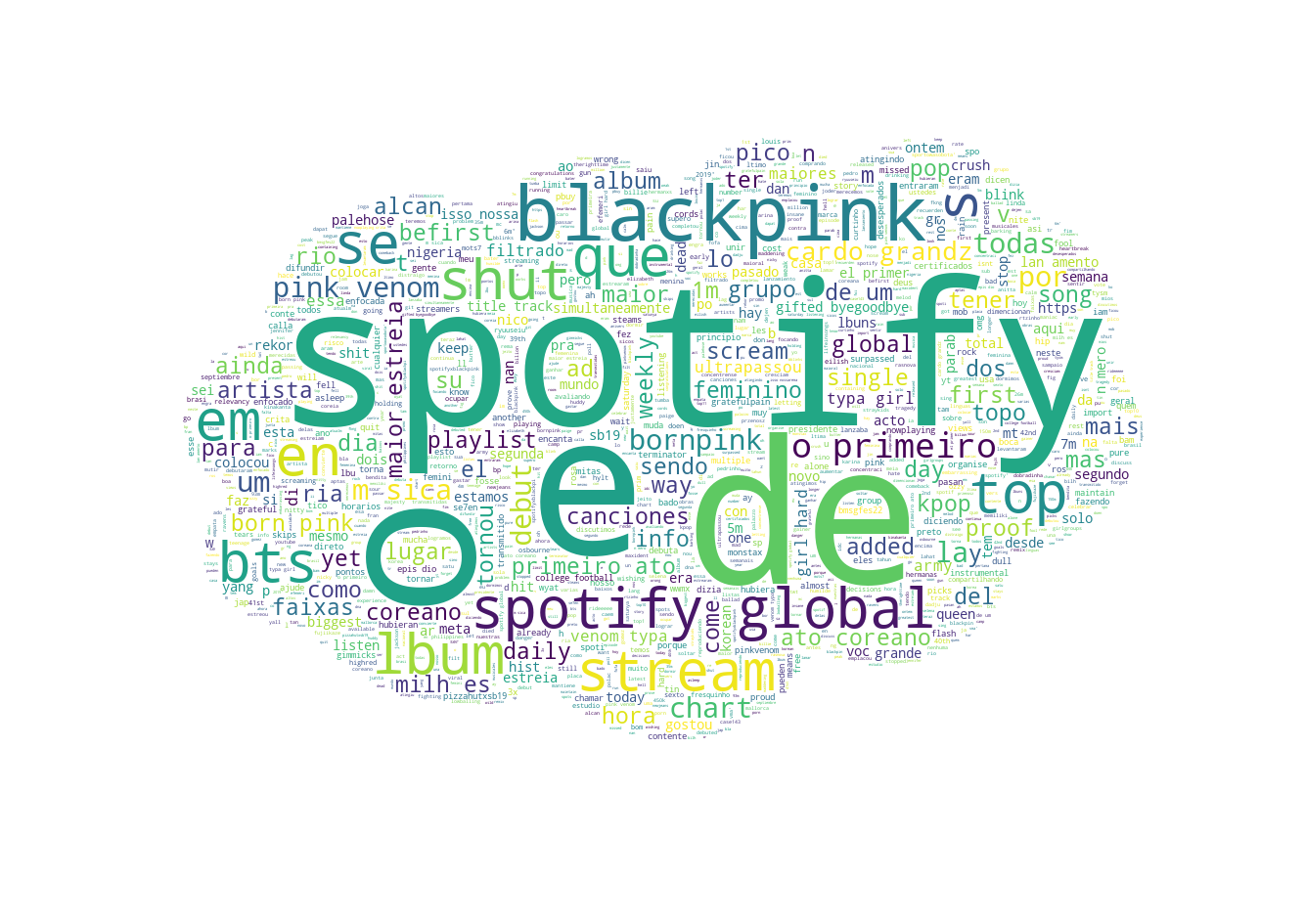
The final version of the Tweets that have a positive sentiment.
Here we can see large trends of what people are voicing their opinions on. Apparently Blackpink was a big topic at the time that the Twitter textual data was fetched. The data checks out, at the time of my data fetching (17.09.2022 23:00 EEST), Blackpink became the first Korean girl group to earn multiple #1 hits on Spotify Global Chart which would atleast partly explain the large interest in discussing the group.
The final version of the Tweets with a negative sentiment
Now a look into Tweets with a negative sentiment, apparently people were Tweeting negative things mostly about waiting and the algorithm. It's important to keep in mind that querying 2000 Tweets results in a timeframe of no larger than roughly 3 hours, and that might skew the results to being one sided.
Discussion
Ideas for improvements I might do in the near future:
Enlarge the sample size to get a bigger sample, maybe it is possible to spot themes that are reoccuring on a larger scale and in that way get a more meaningful and potentially significant result.
Try and implement wordNet in place of PorterStemmer, in other use cases it has proven to result in more accurate match of word origin.
Ngrams to see word association.
Negation detection.
The main structure of the code was implemented from https://github.com/yalinyener/TwitterSentimentAnalysis with modifications to fit the code to work for my application.